
As the coronavirus pandemic entered its second year, a team of scientists from the US Department of Energy’s Oak Ridge National Laboratory used the nation’s fastest supercomputer to streamline the search for potential treatments.
“The approach we used to search for promising molecules resembles natural selection in fast forward,” said Andrew Blanchard, one of the study’s authors. “We focused on two aspects: how to generate new molecules and how to score them according to their potential to inhibit the virus.”
The study earned the team a finalist nomination for the Association of Computing Machinery Gordon Bell Special Prize for High Performance Computing–Based COVID-19 Research. The prize will be presented at this year’s International Conference for High Performance Computing, Networking, Storage and Analysis (SC21) in St. Louis, MO, where the team will present their results Wednesday, Nov. 17.
The team included Blanchard and fellow scientists John Gounley, Debsindhu Bhowmik and Shang Gao of ORNL’s Computational Sciences and Engineering Division (CSED); postdoctoral researchers Mayanka Chandra Shekar of CSED and Isaac Lyngaas of ORNL’s National Center for Computational Sciences (NCCS); and NCCS researchers Junqi Yin, Aristeidis Tsaris, Feiyi Wang and Jens Glaser.
Their study used a deep-learning language model, known as Bidirectional Encoder Representations from Transformers, or BERT, to sort through billions of chemical sequences to find molecules that might block two of the primary protein components of the coronavirus. BERT relied on data recognition and natural language processing techniques honed on Summit, the nation’s fastest supercomputer, to sift through the molecular combinations, each represented as a simple text sequence. That training enabled BERT to perform work in a matter of hours that might have otherwise taken years.
“In this type of language processing, the model has to learn how to infer the meanings of token words from context,” said Glaser, another of the study’s authors. “For example, a sentence might say, ‘The chicken didn’t cross the road because it was too wide.’ In that sentence, ‘it’ means the road. But change ‘wide’ to ‘tired,’ and ‘it’ refers to the chicken. The model has to figure that meaning out from how those words relate to each other in the sentence.”
The team tweaked the model to apply those techniques to the formulas for molecular compounds.
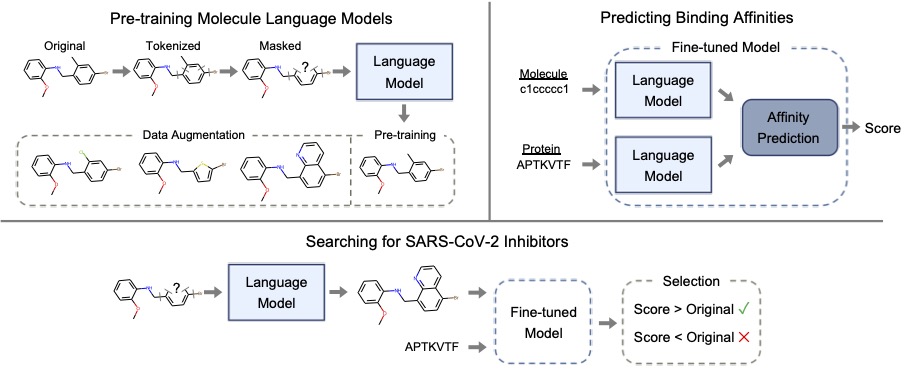
An ORNL study used a deep-learning language model to sort through billions of chemical sequences to find molecules that might block two of the primary protein components of the coronavirus.
Credit: Blanchard, et al./ORNL
“A collection of atoms changes its meaning if the bonds between those atoms change—just like how the meanings of words change based on how they’re used in a sentence,” Glaser said. “The model learns to spot that context, fill in gaps and predict which molecules will work best in what combinations. So it can look at any protein target, such as the key proteins in this virus, and predict the best inhibitors to stop the virus from spreading, listing its degree of confidence for each result.”
The researchers came together in March 2021 when mutual scientific interests crossed paths. Blanchard, Bhowmik and Gounley had worked together on the DOE Cancer Distributed Learning Environment initiative, using Summit to train a language-processing model on pathology report data from cancer cases. Glaser had worked on a multi-institutional team that used Summit to simulate attacking the coronavirus by docking molecules drawn from a list of more than 2.6 billion compounds into pockets formed by the virus’s proteins. Wang and others helped round out the team and support the work to train the model at scale.
“Artificial intelligence and high-performance computer modeling have the potential to revolutionize drug discovery by helping us meaningfully understand the vast amount of available data and reducing the cost of clinical trials,” Bhowmik said. “With the help of Summit, we are accelerating that process.”
Blanchard and Gounley used Summit, ORNL’s 200-petaflop supercomputer, to pretrain BERT on a dataset of 9.6 billion molecules. The huge amount of data—nearly 10 times the size of previous training sets for molecular language models—finished training the model in only 2 hours by running on 4,032 of Summit’s nodes. That process taught the model to recognize the most minute details of the myriad potential molecular combinations.
“The training aspects are what’s most computing-intensive,” Gounley said. “That training won’t have to be done every time. This approach could work for any virus.”
The team continues to refine the model, and biomedical researchers have begun experiments to test the most promising inhibitors suggested by the results. Next steps include tweaking the model to predict how molecules could bind and to provide detailed explanations behind the suggestions and rankings.
This research was supported by the Exascale Computing Project and the DOE’s National Virtual Biotechnology Laboratory, with funding provided by the Coronavirus CARES Act and the DOE Office of Science’s Advanced Scientific Computing Research program. The OLCF is a DOE Office of Science user facility.
Related publication: Andrew Blanchard, John Gounley, Debsindhu Bhowmik, Mayanka Chandra Shekar, Isaac Lyngaas, Shang Gao, Junqi Yin, Aristeidis Tsaris, Feiyi Wang, and Jens Glaser. “Language Models for the Prediction of SARS-CoV-2 Inhibitors.” To appear in International Journal of High Performance Computing Applications, 2021.
UT-Battelle LLC manages Oak Ridge National Laboratory for DOE’s Office of Science, the single largest supporter of basic research in the physical sciences in the United States. DOE’s Office of Science is working to address some of the most pressing challenges of our time. For more information, visit https://energy.gov/science.



