

PI: Sunita Chandrasekaran,
Brookhaven National Laboratory, University of Delaware
In 2016, the Department of Energy’s Exascale Computing Project (ECP) set out to develop advanced software for the arrival of exascale-class supercomputers capable of a quintillion (1018) or more calculations per second. That leap meant rethinking, reinventing, and optimizing dozens of scientific applications and software tools to leverage exascale’s thousandfold increase in computing power. That time has arrived as the first DOE exascale computer — the Oak Ridge Leadership Computing Facility’s Frontier — opened to users around the world. “Exascale’s New Frontier” explores the applications and software technology for driving scientific discoveries in the exascale era.
Why Exascale Needs OpenMP
Open Multi-Processing, or OpenMP, is a vital programming model in developing applications for parallel computing platforms. It provides programmers with a set of routines and directives to tell the compiler — another programming tool that translates an application code such as C++ into the machine code understood by the computer — how to distribute specific functions to different cores of the computer’s CPUs and GPUs. OpenMP is a necessity for bringing science applications that have relied on compilers for node-level parallelism to exascale-class supercomputers. But first, gaps in its functionality had to be addressed to meet exascale development needs. This challenge was tackled by the Scaling OpenMP with LLVM for Exascale Performance and Portability, or SOLLVE, team.
Technical Challenges

University of Delaware associate professor and BNL computational scientist Sunita Chandrasekaran leads the ECP SOLLVE project. Image Credit: Sunita Chandrasekaran, UDEL
Making OpenMP useful on Frontier required the SOLLVE team to overcome a primary hurdle: reconfiguring OpenMP implementations within the open-source LLVM compiler system to target AMD Instinct MI250X GPUs, which were all-new chips never used before in supercomputers. This effort included creating runtime implementations of OpenMP offloading directives that didn’t merely work but that also performed well on Frontier’s GPUs.
“It’s one thing for the code to work without a bug, but it’s another thing for the code to work in a performant manner. You must add effective optimizations to your implementations so that it exploits the full power of the AMD GPU,” said Sunita Chandrasekaran, SOLLVE team leader and a computational scientist at Brookhaven National Laboratory.
Furthermore, the team worked to optimize OpenMP for the latest compute nodes — the individual clusters of CPUs and GPUs that make up the “brains” of supercomputers — which have been evolving faster than the specifications set by the OpenMP Architecture Review Boards.
“Frontier has a ‘fat’ node with a 64-core AMD CPU and four AMD GPUs. Back 10–12 years ago, nodes used to have a lot of CPUs and maybe just one GPU. The one node was so thin you could only do so much before you were traveling to other nodes,” Chandrasekaran said. “But with Frontier, you’re packing more and more rich hardware resources within just one node, so the on-node programming model takes the front seat. You want to exhaust the resources available on one node before you travel to other nodes.”
ECP and Frontier Successes
The SOLLVE team has met all the key challenges set by the ECP, including the ability to target the AMD GPUs on Frontier, Intel’s Data Center GPU Max Series processors in the upcoming Aurora supercomputer at DOE’s Argonne National Laboratory, and NVIDIA GPUs in the Perlmutter supercomputer at DOE’s Lawrence Berkeley National Laboratory. The team worked with the rest of the OpenMP community to design and add offloading features and extensions into OpenMP versions 4.5 and above. They also developed implementations of these features within LLVM and worked with application developers to use these features to enhance their code for Frontier and other systems.
“Over the past five years, we have created a thriving community in the LLVM/OpenMP offloading space. Academia, national laboratories and industry come together to provide a portable and performant implementation and develop extensions that help actual scientists in production. As an example, we are currently integrating a performance-portable implementation of C++ standard parallelism into LLVM that can automatically utilize GPUs and CPUs through the OpenMP offload interface,” said Johannes Doerfert, a computer scientist at Lawrence Livermore National Laboratory and lead LLVM OpenMP offload code owner.
Confirming whether these new implementations matched their original feature descriptions in the standard specification was another key objective for the team. As a result, the team established the OpenMP Validation and Verification test suite. The team wrote functional unit tests to verify whether the implementations created by vendors or the LLVM-based compilers match the definitions of what each feature is supposed to do. They have been conducting methodical validations of all OpenMP offloading compilers and posting the results online.
“There can be a lot of discrepancies between how a compiler developer, an application developer or a specification writer translates the definition of a feature. The test suite aims to capture these discrepancies,” Chandrasekaran said. “Sometimes, a specification has been rewritten because of an issue found by the suite.”
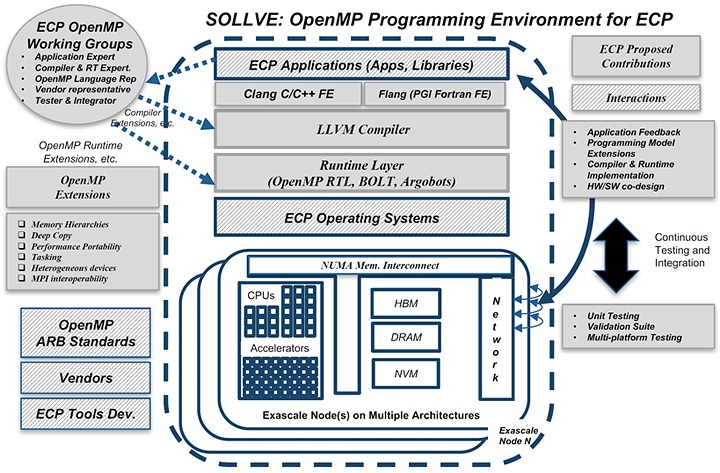
An overview of the SOLLVE programming environment. Image credit: Brookhaven National Laboratory
What’s Next?
While the SOLLVE team continues to work on implementations and performance optimizations for OpenMP, members have also been discussing ways of automating some of its processes. For example, it would be worthwhile to explore AI-based solutions such as large language models to generate nightly V&V and regression tests and send email notifications of potential issues to LLVM developers.
“ECP funding was immensely helpful to keep up what we have been doing. SOLLVE is a big project spanning multiple national labs and universities — in essence, it is a community-driven ecosystem. But since all vendor compilers rely on LLVM, there is no room to stop, so we are pursuing different avenues to keep us going,” Chandrasekaran said.
Support for this research came from the ECP, a collaborative effort of the DOE Office of Science and the National Nuclear Security Administration, and from the DOE Office of Science’s Advanced Scientific Computing Research program. The OLCF is a DOE Office of Science user facility.
UT-Battelle LLC manages ORNL for DOE’s Office of Science, the single largest supporter of basic research in the physical sciences in the United States. The Office of Science is working to address some of the most pressing challenges of our time. For more information, please visit https://energy.gov/science.



