
Using the Summit supercomputer at the US Department of Energy’s (DOE’s) Oak Ridge National Laboratory (ORNL), researchers from the University of Southern California’s Information Sciences Institute (ISI) have made significant progress toward achieving a major goal in scientific high-performance computing (HPC): creating a compiler to more easily port complex science codes between different supercomputer architectures.
Not unlike home computers built with different CPU chips, supercomputers at DOE’s Leadership Computing Facilities often employ different types of components that require software to be optimized for their specific architectures. This can present hurdles to scientists who want to run complex simulation codes on a variety of machines. For example, the Theta supercomputer at Argonne Leadership Computing Facility is based on the Intel Xeon Phi CPU, whereas the Summit supercomputer at the Oak Ridge Leadership Computing Facility (OLCF) uses NVIDIA Volta V100 GPU accelerators. Adapting a code written for Theta’s CPUs to run well on Summit’s GPUs can require extra time, effort, and expense.
ISI’s Compiler Abstractions Supporting high Performance on Extreme-Scale Resources (CASPER) project, led by ISI Research Team leader John Paul Walters, seeks to overcome those hurdles.
“We’ve been working to develop a compiler that takes domain-specific applications and emits high-performance, automatically scalable code,” Walters said. “You don’t want programmers to have to develop their code for one specific supercomputing architecture—you want its performance to be portable across many supercomputing architectures.”
Compilers are software tools used by programmers to take codes written in higher level languages, such as C++, and turn them into machine-level instructions the computers can understand and execute. CASPER’s compiler parses domain-specific languages (DSLs) to reduce the workload typically needed to port software into a different CPU architecture. Because DSLs target particular scientific domains, they give programmers a head start on revamping code because some of the work of integrating the scientific domain’s requirements has already been done.
“DSLs provide an abstraction to whoever is writing that code. So now, suddenly, you have a compiler that knows something about the domain that you’re targeting. You can make optimizations more easily,” Walters said.
The CASPER compiler is being developed around two unique DSLs: Halide, for writing high-performance image-processing codes for apps such as synthetic aperture radar (SAR), and PyOP2/Firedrake/UFL, for writing computational fluid dynamics (CFD) codes. For their work on Summit, the CASPER team tested how far they could scale up the applications to take advantage of the supercomputer’s vast array of nodes. The team had the most success scaling up Halide to 1,024 nodes.
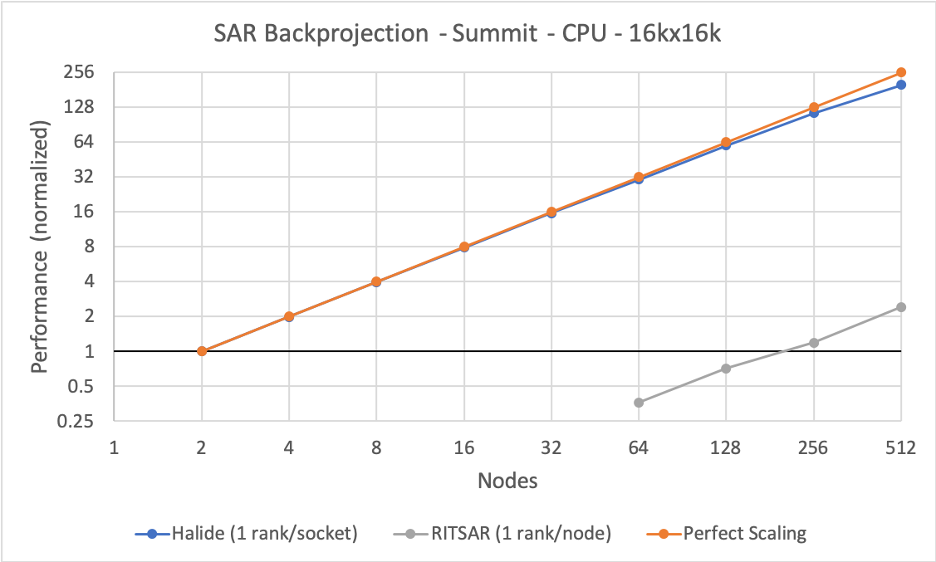
The CASPER compiler is being developed around two unique DSLs: Halide, for writing high-performance image-processing codes for apps such as synthetic aperture radar, and PyOP2/Firedrake/UFL, for writing computational fluid dynamics codes. The team scaled up Halide to 1,024 nodes. This graph for a 16,000 × 16,000 dataset shows a nearly 200× speedup (for a 256× increase in resources), compared with a baseline algorithm called RITSAR. Image courtesy University of Southern California/ISI.
“Our biggest accomplishment so far is we’re getting really efficient scaling on thousands of cores, and we’ve even improved on it since then,” Walters said. “We’re getting a lot of insights into the CFD app’s scaling behavior—we haven’t seen it scale nearly as well as the SAR app, but we’re scaling the radar application beyond what I’ve seen before.”
Now that the ISI team has shown that Halide can scale up on Summit, the team is working to apply the advantages of its DSL approach to the CASPER compiler. A key next step is adding what the ISI team calls a “super optimizer”—an artificial intelligence-based auto-tuner that can identify improved schedules and better mapping approaches to give programmers the best-performing options. It can save time for programmers and improve the efficiency of their applications.
For a researcher writing an SAR app in the C programming language, which lacks any domain-specific optimizations, CASPER can provide Halide’s built-in optimizations—such as single instruction, multiple data vectorization, or GPU implementations—for acceleration. Halide also allows for the separation of implementation and data scheduling—which are usually mixed in C—so that the two algorithms can be tackled separately by different programmers or hopefully by a programmer with the auto-tuner.
“Now you can have the radar person focus on writing the radar algorithm separately from the performance person or auto-tuner writing the schedule,” Walters said. “You can make progress across both of these axes somewhat independently. You don’t need the radar expert to become an HPC expert and you don’t need the HPC experts to necessarily become the radar experts.”
The ISI team’s next goals include adding run time management support to autonomously improve an app’s performance by identifying imbalances and then make corresponding schedule changes. And, of course, Walters would like to start putting CASPER in the hands of researchers.
“My hope is that we can transition this kind of a compiler infrastructure to some of these domain experts so that we can see real applications being implemented,” Walters said. “I think that would also give us some insight into how we could improve on these kinds of applications. We want to continue to push forward and ensure that we’re actually able to support the next-generation applications in these domains.”
CASPER receives funding from the Defense Advanced Research Projects Agency (DARPA) Performant Automation of Parallel Program Assembly program. DARPA is an agency of the US Department of Defense. CASPER also receives support from the OLCF Director’s Discretionary Program; the OLCF is a DOE Office of Science User Facility at ORNL.
UT-Battelle LLC manages Oak Ridge National Laboratory for DOE’s Office of Science, the single largest supporter of basic research in the physical sciences in the United States. DOE’s Office of Science is working to address some of the most pressing challenges of our time. For more information, visit https://energy.gov/science.



