

The sun’s energy is the result of a continuous series of nuclear fusion reactions in which ionized hydrogen in the form of plasma collides at high speeds and releases helium and energetic neutrons—producing enormous bursts of energy in the process.
For years, researchers have sought a way to harness this fusion process to provide an essentially inexhaustible source of clean, renewable energy here on Earth. So far, no fusion devices have been capable of producing a self-heated, burning plasma, in which the fusion reactions themselves maintain plasma heating.
To achieve a burning plasma, a key step for fusion energy, an international team composed of thousands of engineers and scientists are engaged in a decades-long collaboration to construct ITER, a massive fusion device located in southern France. US contributions to the ITER project are managed by Oak Ridge National Laboratory.
For ITER to run successfully, scientists must be ready to address key questions about the nature of fusion reactions. One particular concern in operating a device with 150 million degrees Celsius plasmas is managing the various plasma instabilities that can occur.
To understand the way plasma will behave under these extreme conditions and at such a large scale, researchers often need to rely on computer simulations in conjunction with experiments. However, because of the number of particles involved and the complexity of the physics at work, these simulations can be extraordinarily computationally intensive.
One team is using the US Department of Energy’s (DOE’s) Summit supercomputer at the Oak Ridge Leadership Computing Facility (OLCF), to deploy a method of running these plasma simulations much more efficiently. Princeton Plasma Physics Laboratory’s (PPPL’s) C. S. Chang leads the team, and the other team members are Robert Hager from PPPL, Varis Carey from the University of Colorado Denver, and Robert Moser from the University of Texas at Austin.
High performance computing has been essential for modeling plasma instabilities to inform design and operations for ITER and other fusion devices, and the team’s algorithm, which is applied in Chang’s preexisting particle-in-cell code, XGC, promises more accurate physics with shorter compute times than has previously been possible.
Exploring the edge
When completed, ITER will be the world’s largest tokamak—a type of doughnut-shaped device that relies on magnetic field lines to control the plasma within.
“In a tokamak, the idea is to use magnetic fields to constrain the hot plasma away from the walls of the vessel,” said Robert Moser. “This is really important for a lot of reasons, and it’s a requirement for making a device like ITER work.”
Ideally, plasma in a reactor is confined toward the center of the device with a gap between it and the wall. This way, the plasma temperature needed for fusion to occur remains consistent—a crucial step toward achieving net energy. However, even with the tokamak’s steady magnetic field, this boundary isn’t always distinct, and complicated physics can cause edge plasma to migrate outwards toward the device wall.
As charged particles spin around the tokamak in a helical motion, various instability mechanisms can occur that cause the dumping of boundary plasma energy toward the machine wall. If these instabilities are not controlled, the material wall can erode prematurely, effectively reducing the reactor’s lifetime. Moreover, the plasma temperature can decline within the tokamak as energy leaks out of the magnetic confinement, leading to a reduction in the number of fusion reactions that occur, thus decreasing the reactor’s efficiency.
“The reason plasma in the reactor becomes unstable is essentially because there are such strong gradients,” Moser said referring to magnitude variations in pressure, density, and temperature. “Things change rapidly in space across that boundary, and there is a tendency for the boundary plasma particles to move from regions of high plasma pressure to low plasma pressure. There’s also a phenomenon called turbulence which tends to make things mix, and that’s what the magnetic containment fights against, to keep that mixing from occurring.”
Keeping things even
To understand plasma behavior, Chang’s simulations include “marker” particles that mimic the actual ions and electrons within a reactor. Because the actual number of these particles would be too great for any supercomputer to simulate, each computational marker particle must represent many real-world particles.
Depending on the region of the tokamak being simulated, marker particles are assigned different weights. A marker particle with a heavier weight means it represents more real-world particles, while a lighter weight corresponds to fewer.
“There is a strong density gradient at the edge of the plasma, meaning there is a great degree of variation between areas of high and low density,” Chang said. “To keep the statistical accuracy uniform, we have to keep the density of our marker particles the same across this gradient by assigning them different weights.”
However, a problem arises when the more heavily weighted particles, through mixing and turbulence, begin moving to the lower part of the strong plasma gradient. When this happens, there are too few particles to accurately represent edge plasma physics, the statistical accuracy is lost, and the weights must be rebalanced.
It is at this crucial step that the team’s method, called the moment preserving constrained resampling algorithm, becomes necessary. Developed using the National Energy Research Scientific Computing Center’s (NERSC) Cori and Argonne Leadership Computing Facility’s (ALCF) Theta supercomputers, the algorithm has two primary benefits in fusion simulations.
First, it ensures that the number of computational marker particles in the steep-gradient reactor edge is enough to accurately represent complicated physical states over time. Second, it allows for more efficient simulations by evenly distributing particles across computer nodes.
“Say one node is working very hard but other nodes are idle—then there’s a lot of waste in the computing power,” Chang said. “To run more efficiently, we want to have the number of particles uniform everywhere, with each processor representing one small volume of the whole tokamak. The problem is, when you have turbulence the particles move around randomly, and gradually we lose that homogenous particle number. So, as this goes on, you have some nodes with many, many more particles than other nodes.”
The distribution of work across nodes is an essential part of running a supercomputer like Summit efficiently, as idle cores can greatly increase simulation run times.
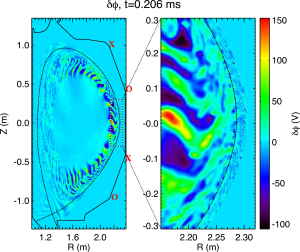
Plasma turbulence in the DIII-D tokamak that was simulated utilizing the new particle-resampling technique. The dashed black line shows the magnetic boundary, the solid black line is the tokamak wall, and the red X and O marks depict the stochastic magnetic perturbation coils alternating in direction.
“What we do is we divide up any computation, for example the tokamak simulation, into individual pieces,” Moser said. “Each processor works on its own little piece, and every once in a while, they communicate with each other. Now, when these nodes communicate with each other, all the different processor cores have to wait while one processor core tells the others that it’s ready to be sent the data it needs, so you end up having a problem if one processor core has more work to do than others, which is why we try to distribute the work amongst the processors evenly.”
This process of distributing work across processors, called load balancing, is key to running longer plasma simulations on extreme-scale computers like Summit that give scientists a better understanding of how a tokamak will perform.
Importantly, the algorithm is not limited to fusion applications, as the problems addressed by Chang’s team are faced in a variety of other physics simulations.
“Hopefully, this algorithm will not only be useful to our code but to many other particle codes which share similar issues like space and solar physics,” Chang said. “There are quite a lot of codes which use the particle-in-cell method, and they all suffer from similar issues where the number of particles becomes unevenly distributed in space during the simulation. So, codes which use particles, most of them can benefit from this technology.”
Applied to Chang’s preexisting XGC1 code, the algorithm holds the possibility of extracting more meaningful physics over shorter periods of computational time, thus maximizing the potential of supercomputer allocations. To enable ITER’s goal of achieving a burning plasma and demonstrating 500 MW of fusion power, it’s imperative that researchers work as efficiently as possible during their time on machines like Summit.
In addition to the aforementioned developers, Chang was assisted in his work by the XGC team, composed of researchers from ORNL, Los Alamos National Laboratory, Lawrence Berkeley National Laboratory, Lawrence Livermore National Laboratory, the University of California at San Diego, the University of Colorado at Boulder, the University of Illinois Urbana Champaign, Rensselaer Polytechnic Institute, and Theodon Consulting. ALCF, the OLCF, and NERSC are DOE Office of Science user facilities.
Related Publication: C. S. Chang et al., “Moment Preserving Constrained Resampling with Applications to Particle-in-Cell Methods,” Journal of Computational Physics 409 (May 15, 2020).
UT-Battelle LLC manages Oak Ridge National Laboratory for DOE’s Office of Science, the single largest supporter of basic research in the physical sciences in the United States. DOE’s Office of Science is working to address some of the most pressing challenges of our time. For more information, visit https://energy.gov/science



