
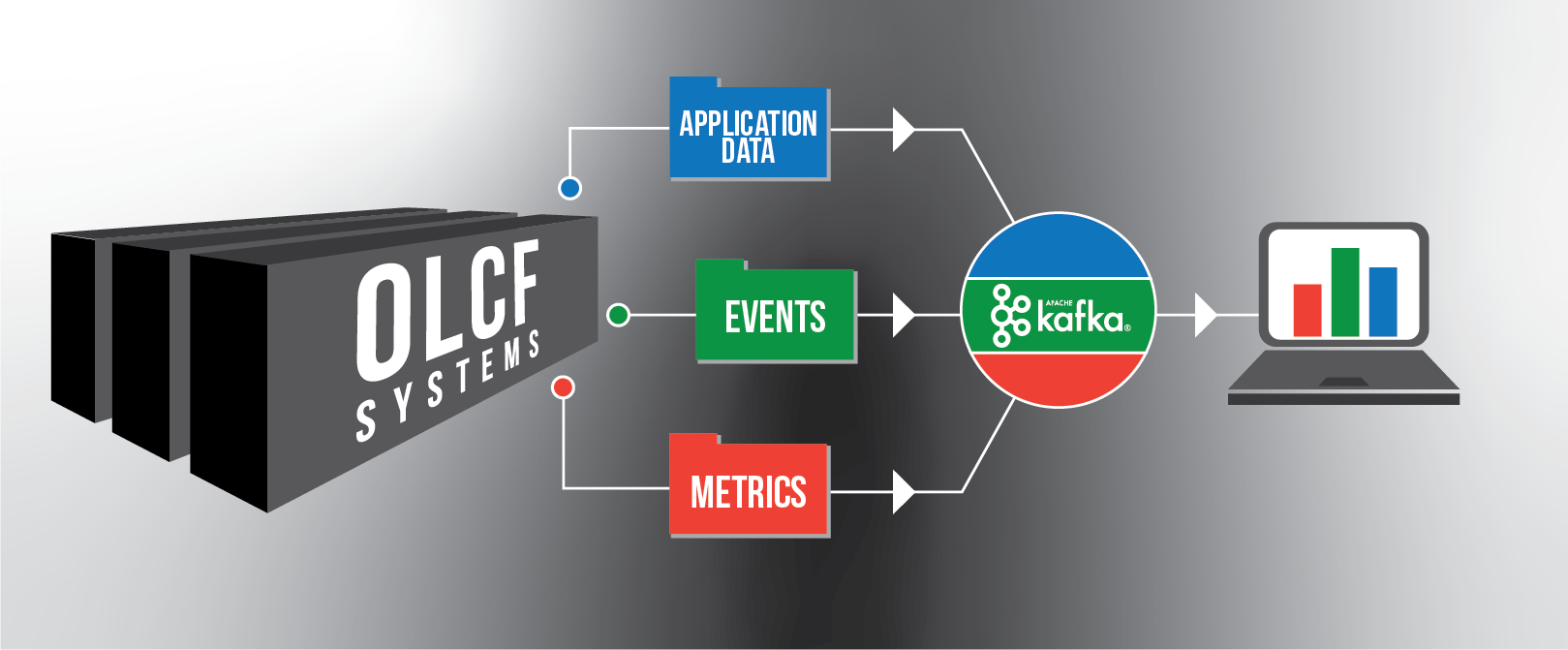
The high-performance computing (HPC) systems at the US Department of Energy’s (DOE’s) Oak Ridge National Laboratory (ORNL) are about to vault into the “pubsub” era of real-time streaming analytics.
Employing the open-source Apache Kafka event-streaming platform, ORNL’s HPC Core Operations (Ops) Group has built a whole new publish/subscribe system for delivering metrics from the supercomputers at the Oak Ridge Leadership Computing Facility (OLCF), a DOE Office of Science User Facility at ORNL. The new “pubsub” system will transform how OLCF supercomputer analytics are tracked, replacing what was typically a slow, manual process for each data pipeline with a centralized, automated information bus that aggregates available data sources for subscribers. The Kafka-powered system promises much higher levels of speed, reliability, and retention.
“We’re making internal business intelligence a first-class citizen,” said Ryan Adamson, HPC Core Ops group leader.
Initially designed as a message platform for the professional networking community LinkedIn, Kafka was donated to the Apache Software Foundation in 2011 and further developed into a low-latency, high-throughput system for delivering data feeds in real time. It has since been adopted by thousands of companies that require robust data pipelines, from Airbnb to Netflix, gaining a reputation for security and scalability. Confluent, a company formed by Kafka’s original development team at LinkedIn, supports an enterprise version of the platform, which was selected for the OLCF’s deployment.
Now, after 2 years of development and testing by Core Analytics and Monitoring (CAM) data engineers Stefan Ceballos and Ryan Prout, the Kafka-powered data-streaming platform is ready for internal OLCF staff members to explore. The experience should prove to be much more user-centric than the previous method of requesting system data, which often meant waiting for new, individual data feeds to be built or connected and then collecting the information in a daily time-consuming process.
“You would write logs to a database for a day and then at midnight you would do the analytics. Then you’d write a report, which would get dumped out to disk somewhere, and then the next day someone would go and look at it,” Adamson said. “It’s very manual and terrible. But Kafka lets the information flow more freely and quickly and in real-time.”
Now, under the new system, a directory of all the available data feeds will allow OLCF staffers to know exactly what they can tap into rather than making a new request each time.
“Before, we had no idea what we were going to be collecting metrics on because it was very grassroots,” Adamson said. “Now we have a data dictionary that specifies what data sources we’re collecting—so if a researcher comes along and wants to do some research, they can see what we have without having to ask the admins to give them this data.”
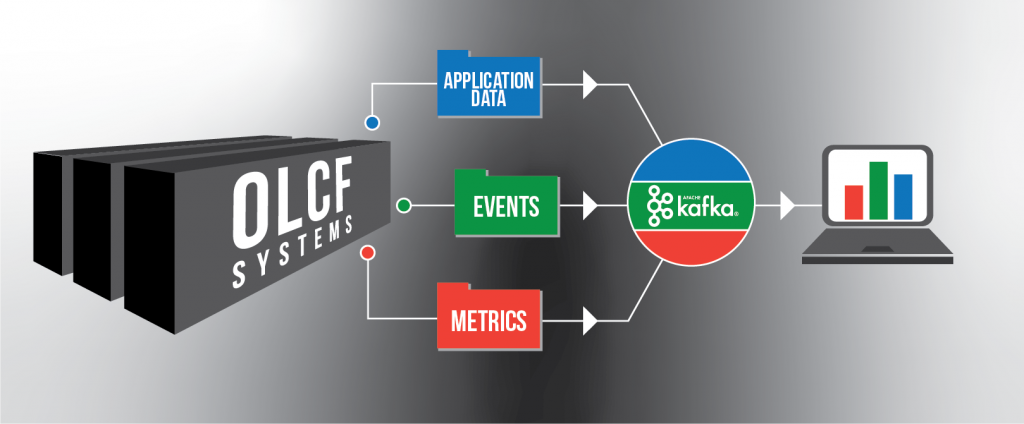
The OLCF’s Kafka-powered data-streaming platform will simplify supercomputer metrics tracking. Image credit: Jason Smith
The Kafka system is currently flowing data streams for the GPU power usage on Summit, the file-system performance on Alpine, and the XALT program, which gathers job data on Summit. The team plans to add new data sources every other month or so, carefully scaling up in a methodical fashion to avoid any hiccups. Preexisting data stores such as Elasticsearch or Splunk can access the streams, though some OLCF staffers may need custom dashboards built by the CAM team to focus on the information they’re most interested in tracking.
This new data dictionary will also provide more centralized organization, which should help avoid miscommunication—previously, OLCF staffers were not always aware of who else might be connected to their data feeds.
“One of the big issues before was that there wasn’t any explicit documentation saying, ‘We’re currently sending data from here to here,’” Ceballos said. “So when one person would shut off a service, it would affect everybody who was connected to it—people wouldn’t know, and they’d go, ‘Why is our stuff not working?’ Now there’s documentation on that and there’s more accountability, but it also gives insights: ‘I didn’t know this data existed, but I can benefit from this.’”
Consequently, the Kafka system should better facilitate the sharing of data between teams for business insights and collaborations.
“The main thing is it’s not going to be so ad hoc as it was previously, so there’ll be a defined path to integrate your data into a production system,” Prout said. “You can still do things locally, but if you want to share with others and have data contracts with other teams, this will allow for that.”
Other internal applications will also benefit from Kafka streaming. The Resource and Allocation Tracking System (RATS) Report, a customer relationship tool that tracks supercomputer users and projects at the National Center for Computational Sciences (NCCS), will see a big upgrade in the immediacy of its reports. Currently, the RATS team conducts a once-a-day input of all job metrics from the previous day—job logs from various machines, file system usage data, downtime events, GPU data, project and allocation data, etc. Now that information will arrive in an up-to-the-minute dataflow.
“Before, you would have to make decisions on the next day based on the previous day’s data. But now we’re getting this stuff in real-time streaming and we’re able to make decisions based on the last 5 minutes of data,” Ceballos said.
Scott Simmerman, an HPC software engineer in the User Assistance and Outreach group who is currently integrating the available Kafka data feeds into RATS Report, said the shift to Kafka will also help gather job data from special sources, such as the Compute and Data Environment for Science (CADES), an integrated computing infrastructure.
“Currently the process for getting job logs from CADES has lots of moving parts and can be a pain to set up and maintain,” Simmerman said. “With Kafka, it’s just a matter of them publishing their job logs to Kafka and then us consuming them—with no files moving around different file systems.”
Once more data sources are connected to the Kafka platform, the CAM team plans to focus on new ways to process and visualize the data, making it easily accessible to NCCS personnel. From there, intelligent applications can be built to make automated decisions based on this data, improving operational efficiency.
“The first phase of any intelligent system is gathering data, so once we gather all this data, we can start putting it into applications that make decisions based on that data over time,” Prout said. “That’s the ultimate goal—to make it an intelligent facility.”
There will be a reoccurring Kafka User Group meeting on the second Tuesday of every month starting January 14, 2020, from 2-2:30 p.m. in Building 5600, Room E202. OLCF personnel can email [email protected] to receive a calendar invite, though it isn’t necessary to attend.
UT-Battelle LLC manages Oak Ridge National Laboratory for DOE’s Office of Science, the single largest supporter of basic research in the physical sciences in the United States. DOE’s Office of Science is working to address some of the most pressing challenges of our time. For more information, visit https://energy.gov/science.



