
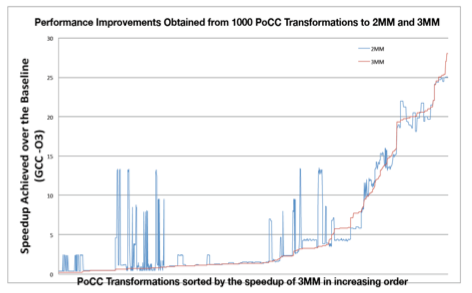
This figure plots the performance improvements for 2mm and 3mm when the development team used the same set of polyhedral compiler optimizations. These two programs have the same classification results using the team’s classifier and show very similar speedup trends from the same set of optimizations.
OLCF tool extracts more parallelism from applications for exascale systems
Programming applications to run on future exascale systems offer a challenge. The concern is whether users will be able to extract enough parallelism from their existing programs to take advantage of the new computational power that will come with these larger supercomputers.
Fortunately for users at the Oak Ridge Leadership Computing Facility (OLCF)—a US Department of Energy (DOE) Office of Science User Facility located at DOE’s Oak Ridge National Laboratory (ORNL)—a team led by Christos Kartsaklis built a tool to address this uncertainty.
Typically, users take a problem and partition it into smaller subproblems, which they’ll run on several different processors—a common practice on systems like the OLCF’s Titan, a 27-petaflop Cray XK7 machine with a hybrid CPU/GPU architecture. This is called extracting parallelism, or parallelizing a problem, explained Kartsaklis, an OLCF software application tools developer. If you take the same problem or program and run it on a system that’s 1,000 times larger, the user’s original plan of partitioning the problem won’t work.
“You might find enough work to extract parallelism from an application for a system of Titan’s size, but as the system grows, you have to look for new things that you didn’t think could be parallelizable,” he said. “To efficiently run applications and take advantage of these more powerful exascale systems, you have to find more parallelizable pieces of the code that currently run on a single processor. That’s the hard part. Thus, the tool that we developed finds parts of the existing code that haven’t been parallelized.”
To extract parallelism, researchers typically use compilers or other analysis frameworks that will look through the source code’s structure and figure out what the code does—called the offline or static approach. Based on that, the compiler or framework can suggest ways to parallelize the code further, which sounds ideal. However, the reality is that source codes for programs can sometimes be too complex and too burdened by dynamic behavior, limiting the overall effect of such static analyses.
Kartsaklis and his team—including EunJung Park, a former OLCF-funded summer intern who has a background in compilers and machine learning—developed a tool that takes a different approach. The idea is to observe how the program accesses memory as it runs on a system to determine whether it resembles a known memory access pattern, which is important because certain patterns are well understood regarding their parallelization. The tool utilizes Gleipnir, a plug-in that studies and analyzes data structure elements to understand the memory behavior of applications. Gleipnir was developed at the University of North Texas by Tomislav “Tommy” Janjusic and continued under OLCF funding during Janjusic’s postdoctoral appointment at ORNL.
“The memory access pattern is a hint,” Kartsaklis said. “It’s telling the user that it found something. You still have to go in and determine if that’s the case, but when you deal with hundreds of thousands of lines of code, you can’t manually go in and search for things. That’s why we developed a tool that mines the source code for computational patterns. It helps the user identify additional opportunities for extracting parallelism from parts of the code. We know how certain patterns are parallelized. All we have to do is mine the code for this opportunity.”
Providing users with hints is valuable, but the team members also wanted to explore the technology they developed as an integral part of the compiler tool chain—generating options for optimization. Compilers are limited in that they don’t have all day to optimize the code. They don’t have the luxury of trying every possible combination, so many users end up going with the default setting, which typically produces good performance improvements.
“When you deal with hundreds of thousands of lines of code, where different parts of the code do different things that have to be optimized differently, optimization can become complex,” Kartsaklis said. “The compiler has a certain timeframe to find the best possible optimization for the entire application, so it has to make quick decisions. It might work well for some parts of the code, but not as well for others.”
Thus, the team decided to use a machine learning technique to build the second part of the tool that determines what the optimal compiler options should be.
“We trained a statistical model based on what patterns are present in the code and how the corresponding application performs under different compiler options,” Kartsaklis said. “The tool can then take an unseen application, extract its memory patterns, and do a correlation to predict what the best set of compiler options should be, given the memory patterns that are present.”
The tool, which was bundled with Gleipnir, had several trial runs with OLCF users when it was first developed, and the team currently is identifying other facility users for additional trials. With this tool, the team is confident that user applications at the OLCF will be one step closer to running in the exascale era when that time finally arrives. – Miki Nolin
Oak Ridge National Laboratory is supported by the US Department of Energy’s Office of Science. The single largest supporter of basic research in the physical sciences in the United States, the Office of Science is working to address some of the most pressing challenges of our time. For more information, please visit science.energy.gov.



