
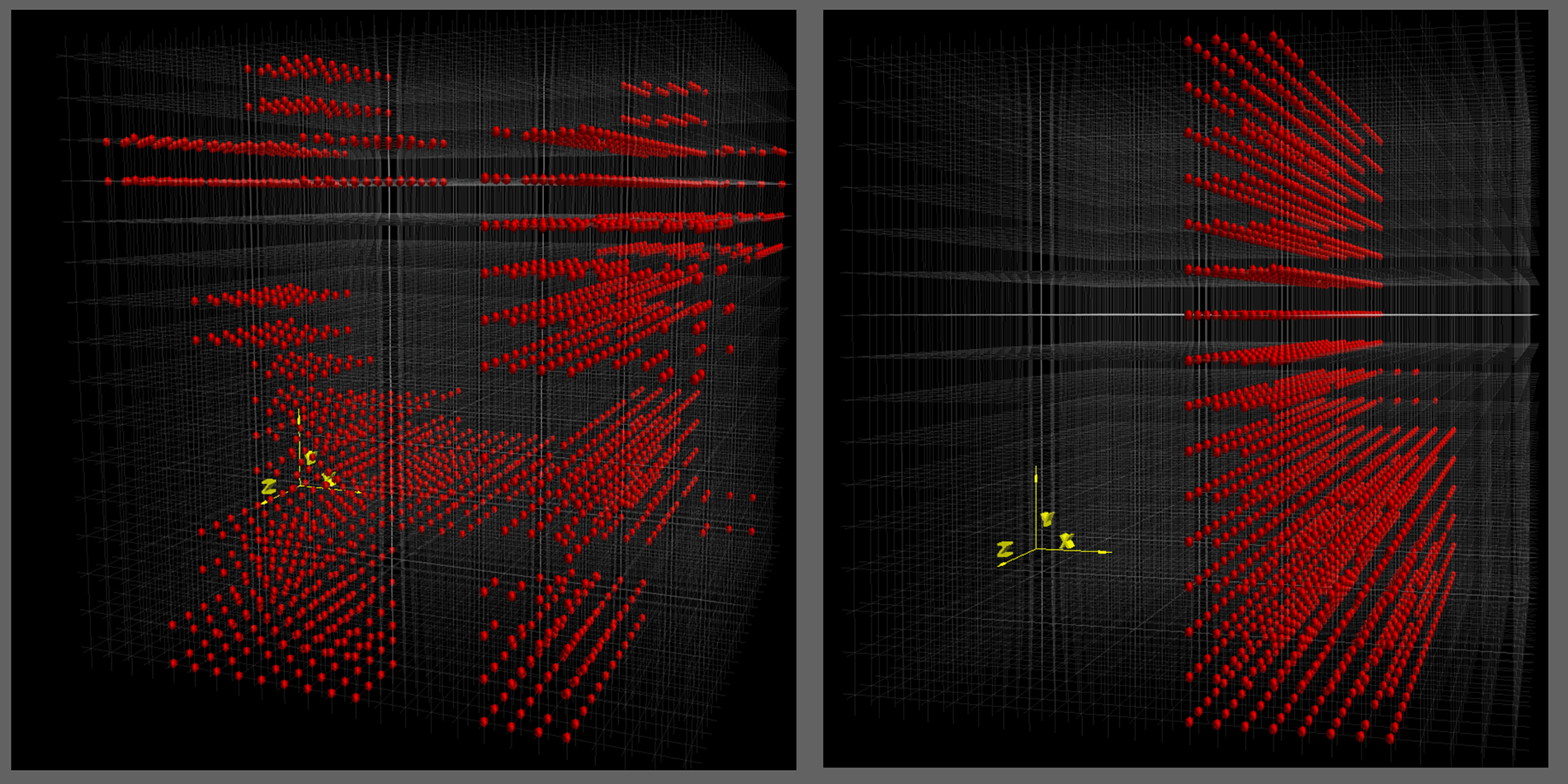
A side-by-side visualization depicting a highly fragmented computing job (left) and a job with reduced fragmentation (right). To reduce fragmentation of large jobs on the Titan supercomputer, OLCF staff is experimenting with how the Moab workload management system schedules jobs. The changes have allowed Moab to allocate large jobs more efficiently.Improvement is measured in the reduction of “hop counts,” or data transfers between nodes, that are needed to complete the job. For example, during a6-week trial the average 4,096-node job on Titan moved 40 to 50 percent closer to the minimum number of hop counts theoretically needed to finish the task.
Parallel computing makes big computational problems feasible by breaking them up into smaller parts. On a supercomputer, these parts share information with one another to find a solution.
Ideally, a high-performance computing (HPC) application would be packed across a supercomputer’s nodes so that it only crossed communication paths with collaborating nodes. But on a leadership class machine, that’s rarely the case. New jobs fill vacant nodes amidst active jobs as soon as the space becomes available. Gaps between communicating nodes commonly arise, slowing down communication and affecting performance.
To reduce fragmentation of large scientific workloads on America’s fastest supercomputer, staff at the Oak Ridge Leadership Computing Facility (OLCF), a US Department of Energy (DOE) Office of Science User Facility, is fine-tuning how jobs are scheduled on Titan. By differentiating between large, long-lived jobs and small, short-lived jobs, new tests indicate Titan is able to do more work in less time.
At any given moment, Titan runs between 30 and 60 jobs of various sizes—from 1,000-plus nodes to 1 or 2 nodes, such as debugging tasks. To regulate the flow of incoming jobs, the Cray XK7 supercomputer relies on the Moab workload management system. Traditionally, Moab keeps a list of all incoming jobs scheduled to run on Titan irrespective of size. When space opens up on the machine, Moab scans from the top of the list to the bottom for a job to fill the vacancy.
“If you think of Titan as a big 3-D grid, you can have various portions of your job spread throughout the machine,” said Chris Zimmer, an HPC systems engineer in the Technology Integration Group at the OLCF, located at DOE’s Oak Ridge National Laboratory. “This is exacerbated by the fact that we have very small, short-lived jobs popping in and out of that list.”
To reduce fragmentation, OLCF staff programmed Moab to schedule workloads differently. Instead of scanning a list from top to bottom, Moab now moves small, short-lived jobs (less than 2 hours) to the bottom of the list, increasing the probability that a large, intensive workload will receive a more favorable allocation.
“It essentially creates a situation where your short-lived, lower-priority jobs run on one end of the machine and your bigger, longer-lived jobs are on the other side,” Zimmer said. “The main benefit of this effort is that large jobs, which are affected more by fragmentation, run faster, and the small ones come and go quickly. Ultimately, the goal is to reduce variability from job-to-job runs.”
During the summer, OLCF staff experimented to find the optimum demarcation point for scheduling small and large workloads. A 6-week trial relegating jobs of 16 nodes or less to the bottom of Moab’s list resulted in improved performance for most jobs greater than 128 nodes, whereas small jobs maintained past performance levels. This improvement is measured in the reduction of “hop counts,” or data transfers between nodes, that are needed to complete the job. For example, during the 6-week trial, the average 4,096-node job moved 40 to 50 percent closer to the minimum number of hop counts theoretically needed to finish the task.
A second trial is under way to determine the effect of raising the demarcation point to 125 nodes. When complete, staff will compare the results of both trials to determine which will have the greatest impact moving forward.
Oak Ridge National Laboratory is supported by the US Department of Energy’s Office of Science. The single largest supporter of basic research in the physical sciences in the United States, the Office of Science is working to address some of the most pressing challenges of our time. For more information, please visit science.energy.gov.



