
Performance analysis tool works at a scale exceeding 200,000 processors
At the Oak Ridge Leadership Computing Facility (OLCF), scientists and engineers run programs, or application codes, on America’s fastest supercomputer. Called Titan, the supercomputer is a marvel of engineering with 18,688 graphic processing units and 299,008 central processing unit (CPU) cores working in concert at a peak speed of 27 quadrillion calculations per second. The codes task the processors to model hurricanes and earthquakes that put people and property at risk, simulate combustion instabilities in power plant turbines and vehicle engines, predict properties of advanced materials, and spur other discoveries and innovations. Titan accelerates breakthroughs in fields in which major advances would not be probable or possible without massively parallel computing.
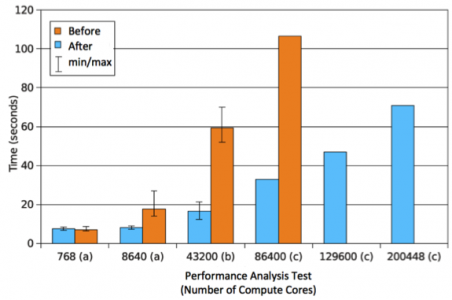
Applying Vampir substantially increased both bandwidth performance and maximum job size. Image credit: Terry Jones
That said, researchers usually don’t begin their computations on Titan. They often start with scaled-down problems run on computing clusters at their home institutions or on partitions of supercomputers that provide access to hundreds of processors at most. They add detail to their models to achieve greater realism, and eventually they need to run the simulation on as many processors as possible to achieve the requisite resolution and complexity. They come to a leadership-class computing facility to do so. At the OLCF they may use a supercomputer with 100 times as many processors as they’ve used before, and they’re expecting their code to run 100 times as fast. But sometimes they find the code runs just three times as fast. What went wrong?
Computer scientists have developed tools to diagnose the millions of things that can go wrong when a program runs through its routines. In May 2012 a team from Oak Ridge National Laboratory (ORNL), Argonne National Laboratory, and the Technische Universität Dresden used Vampir, a software development toolset of the University of Dresden, to analyze a running application in detail as it executed on all 220,000 CPU processors of Titan’s predecessor, Jaguar.
“Understanding code behavior at this new scale with Vampir is huge,” said ORNL computer scientist Terry Jones, who leads system software efforts and works with tools that optimize codes to run on leadership-class supercomputers. Vampir traces events and translates the files into diagrams, charts, timelines, and statistics that help experts locate performance bottlenecks in codes. “For people that are trying to build up a fast leadership-class program, we’ve given them a very powerful new tool to trace events at full size because things happen at larger scale that just don’t happen at smaller scale,” Jones said.
The research team first presented its findings in June 2012 at the High-Performance Parallel and Distributed Computing conference in Delft, Netherlands. The work was published online June 20, 2013, in Cluster Computing. Before this research effort, Vampir could perform this kind of detailed analysis on, at most, 86,400 cores. Large supercomputers use a version of Message Passing Interface (MPI) to communicate between processors. Vampir started as a tool for Visualization and Analysis of MPI Resources (hence the name) but today supports parallelization paradigms beyond MPI, such as OpenMP, Pthreads, and Cuda.
Vampir swoops in on trouble
Performance analysis tools explore what failed where and when. Vampir can troubleshoot Titan-sized machines by setting aside part of the memory of each core so software developers can trace events. A researcher indicates which part of a code is a potential problem area containing performance or logic bugs, and Vampir “turns on” when it enters that part of the code, records details about events, and “turns off” when it leaves that part of the code. The researcher can zoom in on events and identify problems in detail.
“We made it so that when somebody gets access to Jaguar or Titan, if they need to collect information at the scale of the full machine, with Vampir that’s now possible,” Jones said. “They don’t have to collect information on one-eighth of the machine and look at that and scratch their heads wondering how things will change as the code scales to run on increasing numbers of processors. They get to, as part of their code development, do the testing at the full size of the machine.”
Jaguar was #1 on the TOP500 list of world’s fastest supercomputers from November 2009 to November 2010 and in 2012 was transformed through a series of upgrades to become Titan, which headed the November 2012 list. About 1,100 scientists and engineers use the OLCF’s leadership-class machines each year. These researchers, whose backgrounds are often in such fields as physics, biology, chemistry, and Earth science, may need to call on OLCF computer scientists if their codes have trouble scaling up.
One example of an issue that can go unnoticed at small scales but cause trouble at large scales is overuse of barriers, which block any portion of the work being done in parallel from proceeding past a given point until all work has reached that same point. In an analogy in which chefs are mass-producing cakes in a shared kitchen, Jones said, a barrier is equivalent to the chief baker saying, “I can say with certainty that all chefs have their flour, salt, and other dry goods in their bowls at this point.” Added Jones, “For parallel applications running on hundreds of thousands of cores, barrier operations can be very computationally expensive, but you don’t notice them if they’re running on only 20 or 30 cores. It’s easy and tempting to sprinkle unnecessary barriers into the code while you’re parallel programming—I’ll throw in a barrier here, I’ll throw in a barrier there, and there—and people have too many barriers in their code.” The programmer would need to determine if that barrier is really needed and, if so, if anything can be done to speed up operations in that part of the code.
Vampir dramatically increased the ability to capture what’s going on inside a running program, allowing Titan’s user community to expose such problems. Further, these latest tool advances, which are described in the two recent publications, drove a stake through the heart of an input/output, or I/O, problem of getting massive amounts of data in and out of processors. This game-changing contribution allows Vampir to suck more information from data arteries than it previously could.
But Vampir had its own challenges when it initially touched the massive parallelism provided at ORNL. When Vampir is diagnosing a program, it first captures events into memory. But if the memory portion set aside for events is exhausted (either by a long-running application or by dialing Vampir to capture very fine detail about what’s happening), the program must pause while the huge amounts of event data are written to the file system. This transfer of data between memory and file system is a challenge of its own when performed simultaneously with more than 200,000 instances. The team made enhancements that allow that procedure to happen quickly and trouble-free. “You’d like for that data stream to be going over a bunch of fire hoses as opposed to a few straws,” Jones said.
The project’s team members were Jason Cope, Kamil Iskra, Dries Kimpe, and Robert Ross of Argonne National Laboratory; Thomas Ilsche, Andreas Knüpfer, Wolfgang E. Nagel, and Joseph Schuchart of Technische Universität Dresden; and Jones and Stephen Poole of ORNL. They used a Director’s Discretion allocation of 7.3 million processor hours in 2011 and 2012 on Jaguar. The I/O Forwarding Scalability Layer project, the aspect that increased Vampir’s I/O data stream, was funded by the Advanced Scientific Computing Research program in the Department of Energy’s Office of Science. The work to make Vampir function on Jaguar and Titan was funded by the OLCF through a contract with the university at Dresden.
Related Publications
T. Ilsche, J. Schuchart, J. Cope, D. Kimpe, T. Jones, A. Knüpfer, K. Iskra, R. Ross, W. Nagel, S. Poole. 2013. “Optimizing I/O Forwarding Techniques for Extreme-Scale Event Tracing.” Cluster Computing. DOI 10.1007/s10586-013-0272-9
Y. Tock, B. Mandler, J. Moreira, T. Jones. “Design and Implementation of a Scalable Membership Service for Supercomputer Resiliency-Aware Runtime.” Euro-Par 2013 Parallel Processing: 19th International Euro-Par Conference, Aachen, Germany, August 26-30, 2013: Proceedings. Springer, 2013.



